一个小有意思的图片爬虫
爬取静态网站的图片方式其实很简单,就是将HTML页面里面的图片url找出来,并且一张张下载下来就好了,下面给出具体的做法:
首先我们打开这个网站:https://www.vmgirls.com/
这是他的主界面:
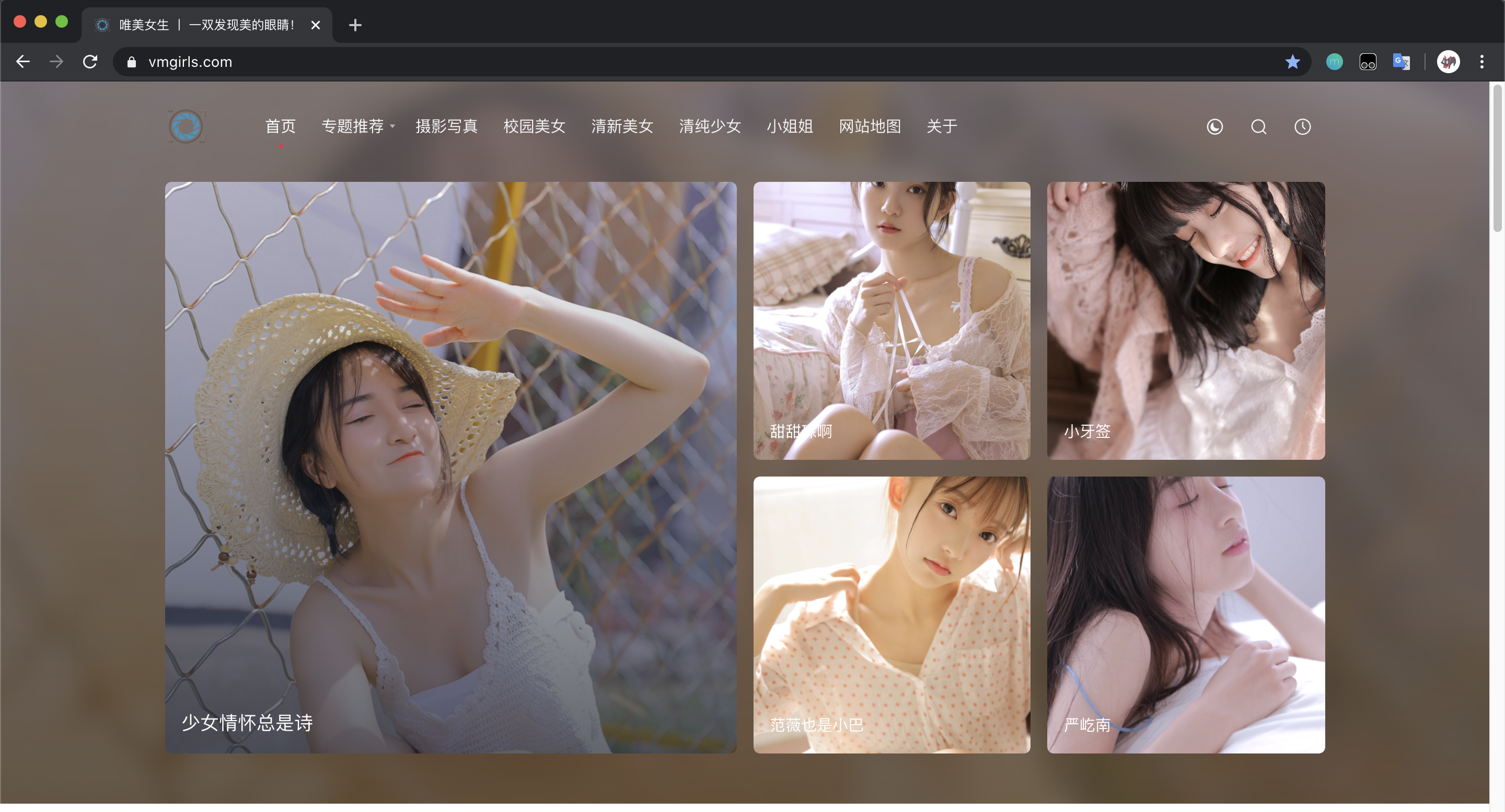
可见这是一个适合年轻人学习爬虫的好网站呢
检查源代码
首先按照惯例,我们去分析网页里图片部分的源代码,这里我们爬取第一个,少女情怀总是诗里面的图片,首先我们点进去,右键一张图片,并且检查元素或者检查源代码:
可以看到这样的代码:
1 | <img src="https://static.vmgirls.com/image/2019/12/2019122210294290-scaled.jpeg" alt="" data-src="https://static.vmgirls.com/image/2019/12/2019122210294290-scaled.jpeg" data-nclazyload="true" class="loaded" data-was-processed="true"> |
https://static.vmgirls.com/image/2019/12/2019122210294290-scaled.jpeg 这一段url即为我们要找的图片地址,我们只需要将这样的url全部找出来,并且下载到文件夹里就好了
编写代码
首先给出我们需要的库:
1 | import requests |
其次,我们写一个函数,这个函数专门负责将网页的内容爬取下来:
1 | def getHTMLText(url, kv): |
这段代码非常简单,仅仅就是爬取了网页的内容,其中kv是个键值对,后面会讲到用途
接下来我们写一个找出这些图片url的函数:
1 | def Ulist(html): |
这个函数里就简单的用到了正则表达式,re.findall()这个函数在后面的博客会讲到,现在只要理解这个函数是用来表示正则表达式的,他的第一个参数即为正则表达式,后一个参数是待匹配的字符串。
这个正则表达式的意思是:
匹配开头为https://static.,中间为.*?,意思所有的字符匹配,并且为非贪婪模式,末尾是.jpeg的字符串,即为我们要爬取的图片格式
接下来我们写一个将这些url下载到文件夹里面的函数:
1 | def save(info, i, kv): |
这段代码即为吧图片存到文件夹里,其中主要的就是try里面这一段,
1 | file_name = url.split('/')[-1] |
这一段为给图片起个名字,这里图方便就直接用url里最后一个\后面的内容,这个是字符串的基本操作
接下来就是打开文件,写入文件里了,res.content是图片的二进制格式,我们直接将它写到文件里,如果有的url报错,没有下载下来,那么会跳转到except执行,即continue
最后是主函数,主函数负责url的翻页操作,还有headers的伪装:
1 | def main(): |
首先这个网页有7页,后面的url即为最开始的url里面加入page-页码,用上述的循环条件进行每一页的爬取
kv是一个伪装头,他会告诉网站我不是爬虫,实测如果只用一个头会被禁止访问,所以再循环里我们改变一下(也不确定是不是这个问题,不过改过后确实解决了被禁的问题),
源代码
这里给出源代码:
1 | import requests |
成果展示
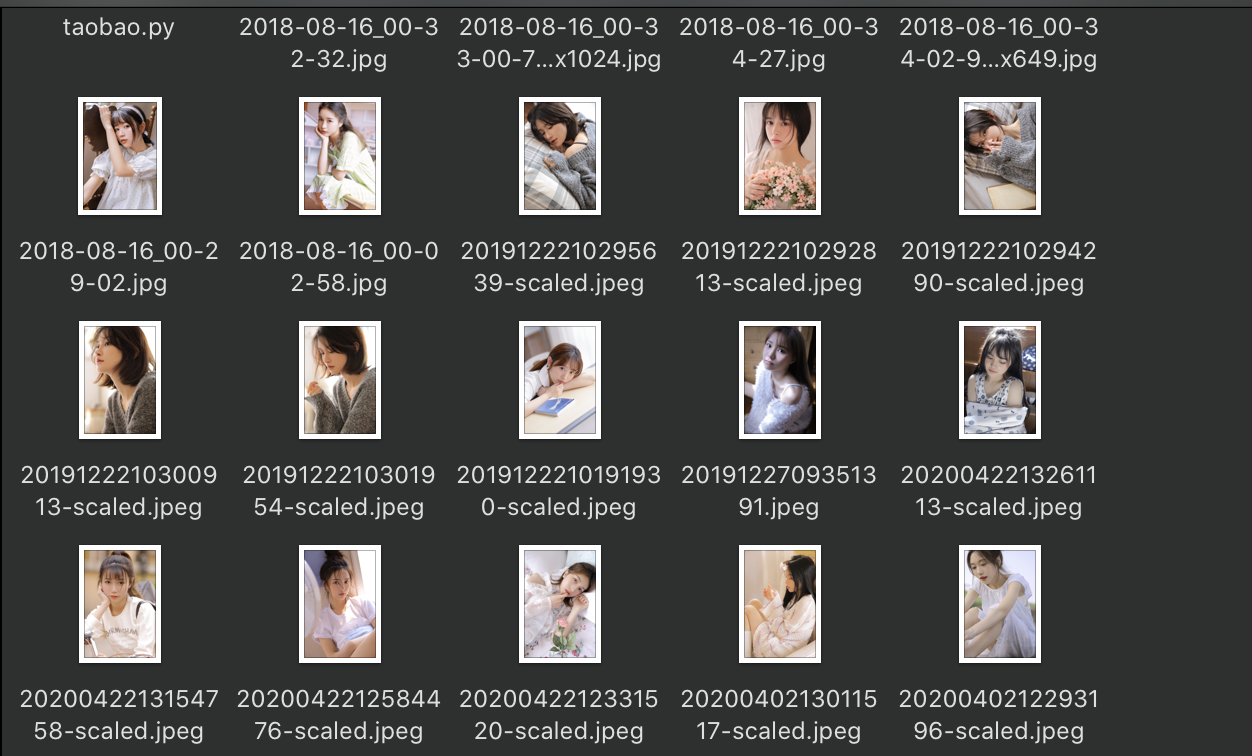
我们的这个爬虫就到此完成
值得注意的是每个网页里都有重复的图片,我们爬下来时因为名字是相同的,所以被覆盖了